Revealing the Method in the Madness
1y ago•
bullish:
1
bearish:
0
Share
The big advantages that Web3 and rollups gain from Syscoin

Long ago, it seemed like madness to some people when the Syscoin project determined that layer 1 of the blockchain stack should ideally represent a court system instead of a transaction processor — the opposite of practically every other blockchain out there. We went against the grain of many mass-marketed third-gen blockchains of that time, even some still today, with our assertion that the base layer is best suited to serve users with repudiation of state decisions, means of governance, and to guarantee censorship resistance for users’ layer 2 accounts. Having witnessed both the evolution and arguably plenty of deterioration in blockchain technology since the beginning of Bitcoin, the necessity has only become more apparent for a steady and decentralized (albeit slow) layer 1 supporting the scaffolding of a fast and convenient layer 2. The Syscoin Platform took incremental and tactful steps to achieve its optimal design for a distributed financial computer with a fractal/modular tech stack. As such, at one time Syscoin’s competitive advantage over the sea of alternative L1s was not so obvious to casual onlookers, until now.
Syscoin’s Lead Core Developer and Foundation President, Jagdeep Sidhu, elaborated on Syscoin’s overall design in an earlier blog. He also covered the modular tech stack, laid out the ideals in designing a modular tech stack and extrapolated to show how the properly designed blockchain can be scaled to flourish far into a future incorporating AI and smart cities, and even support interplanetary civilization. Now let’s combine all of this and show a proof-of-concept. A combination of BLS digital signature, Zero-Knowledge, Data Availability, all combined with a PoW+PoS strategy, becomes something tangible.
Demo
The method emerges from the madness as the solution comes to life!
Let’s show it in practice. Then we’ll dive behind the scenes into all the details for those who want to understand the significance of everything happening here.
https://www.youtube.com/watch?v=Mjfei_l9mpI
Bedrock optimistic rollup + PoDA + Pali Wallet 2.0 + Bitcoin merge-mined security + Finality
What you’re watching is a demo of our open-source free-to-use self-custody wallet (Pali 2.0) working with our layer 2, an Optimistic Rollup (Bedrock-based deployment) using Syscoin’s Tanenbaum testnet! A lot is happening behind the curtain, from creating a two second confirmation, batching transactions into our Data Availability solution, PoDA (also checking against that in the derivation to sync with layer 1), using Pegasys DEX to do swaps in real-time against contracts deployed on Bedrock, creating finality on the Syscoin blockchain to prevent any rollbacks every twelve and a half minutes, all whilst being secured by Bitcoin’s hashrate through merged-mining!
This demo took place on the Rollux OPv2 private testnet. We expect to transition this to public testnet soon. Stay tuned for that! In the meantime, feel free to experiment with Rollux OPv1 which is currently live on public testnet. You can get connected here, then get some test RSYS tokens before heading to the Rollux Pegasys DEX to try it out!
Optimistic Rollup with PoDA (Proof of Data Availability)
This represents a general design for a layer 2 using PoDA on Syscoin layer 1. The process can be applied with ZK-based rollups (we have prototyped this with Hermez zkEVM) the same as we have applied with Optimism Bedrock. Since Optimistic rollups have some advantages over zkEVM right now due to the overhead of ZK proving, we chose to integrate with Bedrock to begin, and will introduce a hybrid solution likely along the lines of Bedrock/Hermez/zkSync upon emergence of hardware-efficient ZK proving solutions. We feel the Bedrock design is currently the cleanest, most secure and efficient of any of the many rollup designs today.
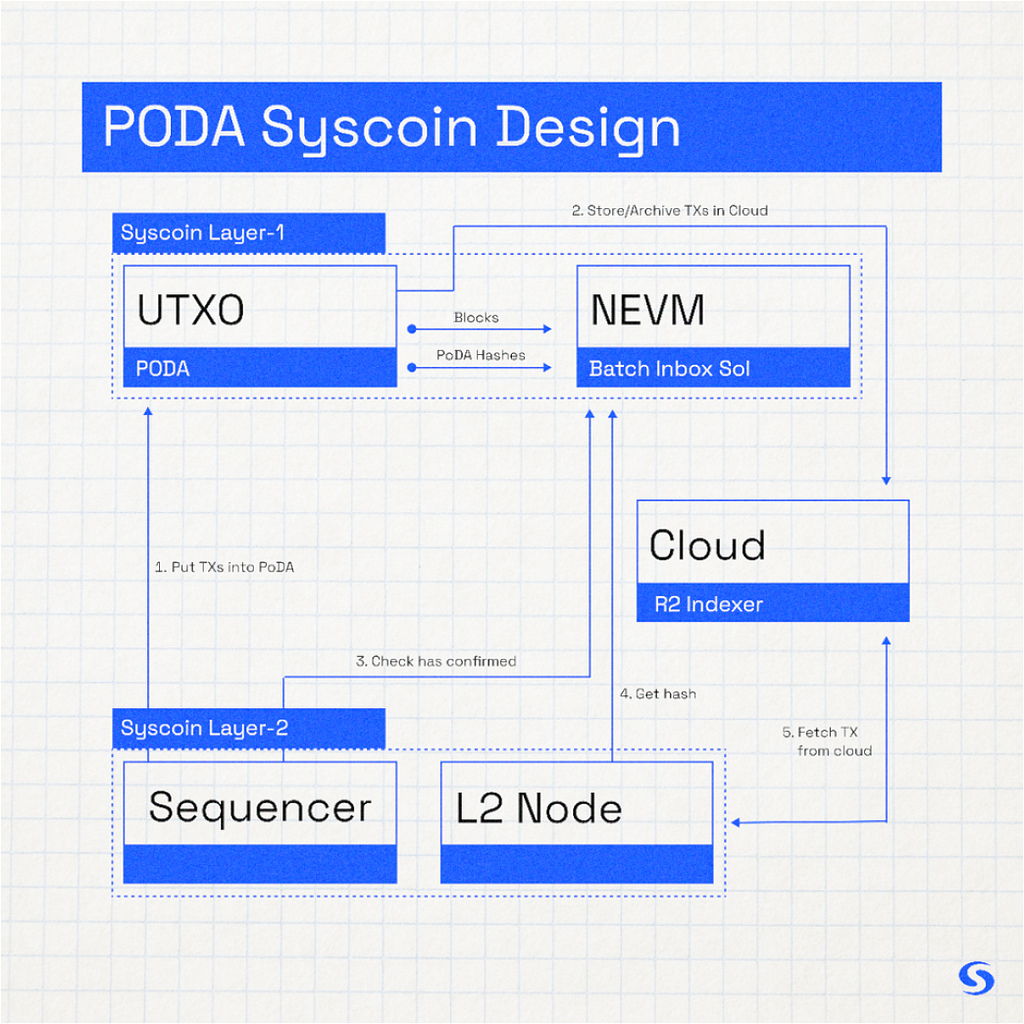
Again, bringing all of this to life has been a complex process we’ve iteratively worked toward. The base layer required a working mechanism for decentralized finality, hash-based blobs and an EVM that is stable and able to provide censorship resistance to rollups on layer 2 and beyond. We released finality + EVM in our NEVM release (Syscoin Core v4.3) in December 2021. Our next Core release will add data availability to mainnet in the form of PoDA, and will be accompanied by an optimistic rollup, showcasing a working implementation of Syscoin’s entire base layer strategy. To integrate PoDA, we assessed the Bedrock codebase of Optimism and created our initial integration (see the diff of our Tanenbaum official testnet deployment). The gist of the integration is summed as follows. This allows us to easily integrate PoDA into any rollup systematically. You can follow the graphic above with the explanation of the numbered sequences below.
- The sequencer (responsible for preserving the order of the unsafe blocks on the rollup, and enabling data availability) sends raw transactions to PoDA (on our UTXO chain) which confirms the blob via its Keccak hash. Data lookup can be performed in the NEVM via a precompile by its Keccak hash. He would create blobs (for now he creates just 1 per L2 block) but theoretically the sequencer can create multiple blobs at once.
- An ancillary service is running to get the blob data from the UTXO chain to throw it in an indexer. Anyone can do this, and only one honest person needs to do this for the design to remain censorship resistant. We use Cloudflare R2 which is a distributed database for our initial bedrock release.
- Upon confirmation of the blob, the batcher calls a smart contract for data lookup to ensure the blob is available on the network. In Bedrock’s case, we called this BatchInbox.sol. Simply put, it allows an array of Keccak hashes to be passed in via standard calldata. It loops to check they exist on the network via a precompile. The data availability is now preserved and the hash of the data is stored in the calldata of the call to the smart contract that verifies the data exists. Theoretically since it can process an array of hashes you can process multiple blobs here. Note that the UTXO chain can process up to 32 blobs of 2MB each but if you process more than that you simply need to wait for confirmation for all of the blobs prior to checking for confirmation of the data via BatchInbox.sol.
- The L2 Node derives the state deterministically via the underlying chain reading the BatchInbox call (filtered by the address of the batcher to ensure its not responding to calls from other addresses). We can fetch the Keccak blob of the hash, check that the contract executed successfully. That means the data existed and was sent by the sequencer at the time of the creation of L2 blocks.
- Then we fetch the data from any indexer that has archived it. We run one by default storing the data in the cloud via Cloudflare R2 but we can preserve the data in any way including Filecoin or decentralized stores as well. It can be anybody storing this data and providing it as a service.
- Upon receiving the data from an indexer, we rehash it to check that it is consistent with what was given to BatchInbox. We then process it as normal by deserializing the rollup transactions and putting them into rollup blocks.
The underlying mechanics don’t change much from what we called OPv1. Previously the data was stored in the calldata of a transaction on Syscoin NEVM. Now that method is replaced with a contract call to check if the hash exists as a blob. The derivation of data changes from fetching it from the calldata of an EVM transaction, to fetching the hash instead, then looking up the data from an external indexer via that hash.
The simplicity of integration this offers will enable us to integrate other rollup designs fairly easily, including natively plugging-in our Keccak blob mechanism to Hermez zkEVM (a state-of-the-art ZK Rollup design with the Plonky2 prover) and others (zkSync, Scroll.tech, Starknet, once they are open-sourced). Then we can approach our own informed model as we combine Optimistic with ZK in appropriate ways (ie: unsafe blocks secured via fraud proofs, and validity proofs secure the system once the unsafe blocks are stored through PoDA).
PoDA generically allows us to have censorship-resistance of data for rollups. This means censorship-resistance that ensures users can exit the rollup, preserving the security provided by Syscoin’s layer 1. As game-changing as that is in itself, the implications extend further, to other things like storing business rules on a public system for censorship-free permissionless auditing of regulation-compliant EVM rollups (stay tuned for that!), and more.
Pali Wallet 2.0
The current Pali Wallet, version one, already has more than 30,000 monthly active users. The next major release of Pali Wallet will enable users to securely manage their cryptocurrencies across both EVM and Bitcoin-core based blockchains, including Syscoin (SYS) and Syscoin Tokenized Assets, Bitcoin (BTC), Ethereum (ETH) and ERC[20,721,1155] tokens, and will enable users to interact with Web3 decentralized applications (dApps). The design of Pali Wallet 2.0 is focused on simple UX, efficiency and speed that are compatible with one-second blocks, and privacy enforcement without data collection. Given that some crypto extensions and stores are now tracking users, we will offer a very easy way to install the extension locally without relying on application stores and their discretionary censorship.
Overall System Design
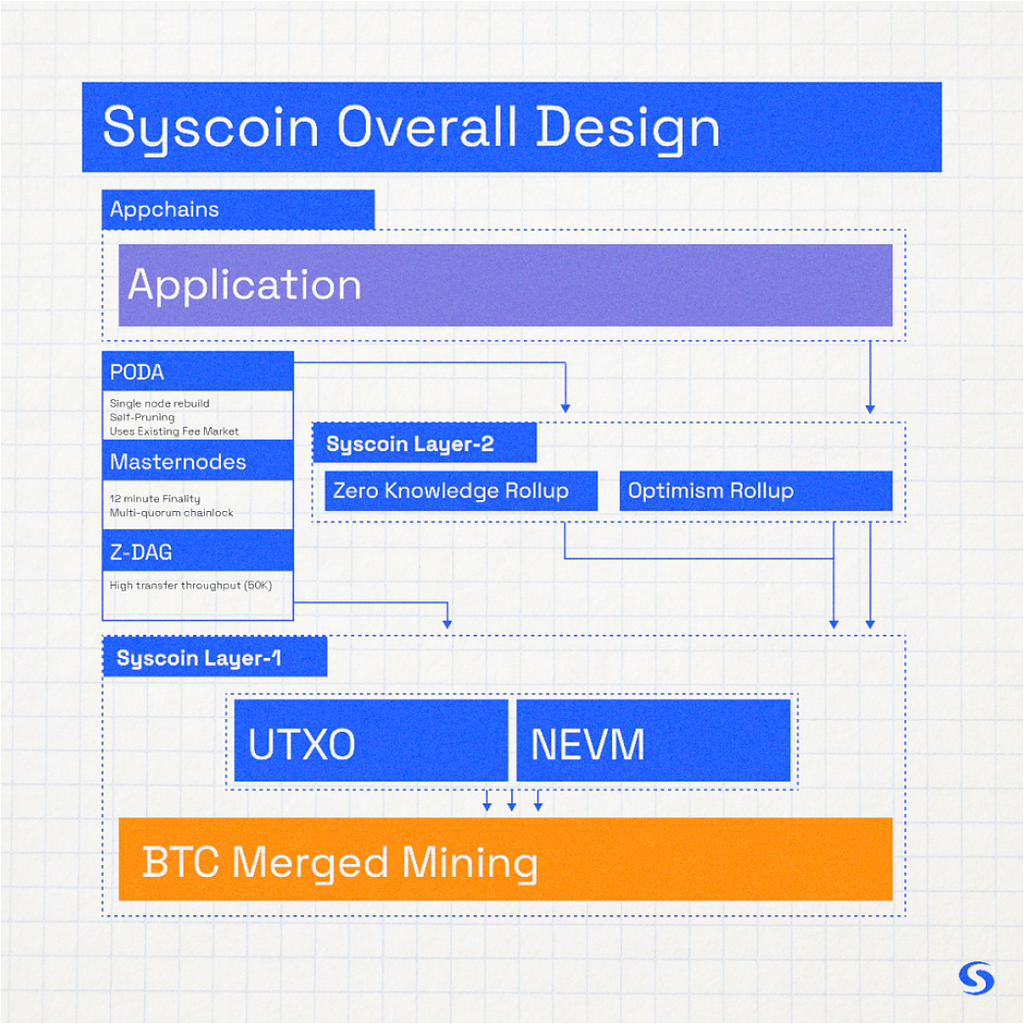
Re-iterating from previous posts, we are basically taking the best of Bitcoin (security through merged mining), applying finality to solve for selfish-mining, and combining all of this with the best of Ethereum (its roadmap towards modularity — Optimistic and ZK Rollups), and Syscoin’s own efficient Layer 1 data availability in the form of PoDA (Proof-of-Data-Availability) which is a stark contrast to Ethereum’s danksharding.
Note that PoDA transactions are just regular transactions; Syscoin does not shard the data nor does it need a new honest majority assumption on the data nor its inclusion on the blockchain. The Syscoin layer 1 philosophy includes the idea of a full node only trusting itself, thus all full nodes review the entire data set for censorship resistant information of layer 2/layer 3 running on top of Syscoin NEVM. To do so, we use hash-based blobs (which we will expand on below). Not only is this performant enough to parameterize Syscoin for global adoption of secure, decentralized settlement of smart contracts, it also eliminates the need for trusted setups. Plus, finality is quantum-safe without introducing new/extra/unproven cryptographic assumptions. Our NEVM chain was launched providing only an 8M gas limit on L1 blocks — half of Ethereum’s current gas limit, with a block target significantly longer at 2.5 minutes (of course dynamically adjustable by miners in majority). By this, we will prove you can scale up without requiring huge blocks on L1. State transitions of L2 are tiny. This means Syscoin will remain nimble, efficient, and easy for regular off-the-shelf computers to sync with, fostering decentralization.
Now, two very important concepts should be explained in regard to Syscoin’s design. These are Finality and Data Availability. We’ll dive into what they are, how Syscoin provides them, and how they relate to each other.
Finality — Multi-Quorum Chainlocks
Recall in an earlier post, Jagdeep Sidhu explained that Syscoin’s masternodes are validators that run as full nodes. This increases the Nakamoto Coefficient (a measurement of the degree of decentralization of disparate services/nodes). These full nodes do not trust others through consensus, rather they each reproduce their own local state in order to verify the chain. This aligns with our ideals. In contrast, things like sharding or relegating consensus to PoS do not. We are PoW at our foundation and know that in order to preserve long-term decentralized contracts with the world we must tie the computational integrity of the ledger to the tangibility of a race for physical energy extraction. Understanding that, the right questions right now are how does Syscoin’s finality work in a decentralized way, and how does it not relegate consensus into a system that is effectively PoS?

You can see above that every fifth block gets “locked”. This is accomplished by the following. Four quorums are formed, each consisting of 400 randomly selected masternodes (1,600 total). Masternodes are deterministically assigned to quorums and the quorums are periodically reordered. Masternodes cannot change the order of when/where they are put into quorums. These quorums form BLS signatures to sign a vote on the state of the blockchain every fifth block. Basically, they vote whether they see the same block at the same height. When at least three out of four of the quorums agree, this is aggregated into one final BLS signature. The rest of the network sees the final signature and validates that the quorums are in agreement. The validators inside each quorum get from others only the information they need in order to create the BLS signature. This has been proven on our live mainnet for over a year to be a wonderful way to efficiently vote on the state of the chain.
Even so, let’s don our tinfoil hats and think about adversarial and worst-case scenarios! Say a super-majority (> 66%) of masternodes collude to censor the blockchain. Technically, if one were to attack in this way, they would likely vote to lower the difficulty so much that it would be easy to mine the chain on a standard CPU, then censor as needed (pick and choose which transactions to allow into blocks and prevent all others). Syscoin’s resistance to this attack resides in the fact that the Syscoin network votes only on the fifth block back from the tip. It is almost impossible to selfishly mine in advance yet have control over the fifth. One would need to dominate both Bitcoin’s miners that are merge-mining Syscoin AND control the majority of Syscoin masternodes. In effect we have increased our security from miner (PoW alone) to miner (PoW) + validator (PoS), and as it seems, without drawbacks.
However, not all hope is lost yet for attackers. Before we dive into the next scenario, let me first describe why it’s especially important to secure PoS completely while PoW self-heals, enabling some “fuzziness” within its security domain.
In a pure PoS system it is critically important that faults do not occur. This means a PoS system has to be perfect in order to prevent people from gaining the ability to decide the fate of the system, censor/stop/halt, or spam the chain as they see fit. Once a PoS system is compromised, it cannot recover. On the other hand, a PoW system relies on the antifragile longest chain rule. One can selfishly mine but that work gets thrown away once overpowered by peers, or one keeps paying very high premiums with little to no return for doing so. It is antifragile in part because it recovers without external help. Syscoin masternodes effectively run a staking model that has access to locking the chain, so they do have some power in our system, but ultimately the miners decide how the chain progresses, so we retain antifragility. Since masternode have this power, proper design is required to rule-out creating scenarios where our system could run into a brick wall. Even if the chance of that happening is very remote, we do not want a layer 1 system that relegates down to depending purely on PoS alone.
Now let’s analyze the next attack — a halting scenario. Let’s say attackers purchase masternodes en masse or otherwise gain control of a super-majority (> 66%). Like all masternodes, the way they vote for the chain begins by receiving a block header and checking its PoW. If it’s valid, they will vote on the block without waiting for its contents. This is for performance reasons — otherwise, blocks with a large data footprint would result in longer turn-around-times to achieve finality, every node being required to have the complete block. However, checking just the header presents a problem. What if the block was purposely created incorrectly? IE: a chain of five blocks selfishly mined with valid block headers but invalid content (say a double-spend transaction). If the masternodes voted for this specific chain and its fifth block to be locked, then every node would have to switch to this invalid chain, effectively halting the chain. To solve this scenario, the protocol enables rolling back to the previous chainlock, but no deeper. The previous chainlock is proven valid by the fact it has been built on and processed by nodes, thus the scenario of two invalid chainlocks in a row is ruled-out. When a new chainlock forms, the previous chainlock must be valid and part of a fully valid chain (not just headers). Therefore, the network can always roll back to the previous known good state in this attack scenario.
Let’s recap the two attack vectors with detailed examples. To avoid our system effectively becoming PoS, we tied chainlocking to every fifth block, buried five blocks. IE: block 1004 is mined (no chainlock), 1005 is mined (1000 is chainlocked), and miners cannot roll back deeper than that even if mining selfishly. In the second vector the masternodes collude to try to accept a selfishly mined block as the chain tip to effectively halt the network. Example: they selfishly mine block 1000 with valid header but with invalid block contents, then mine blocks 1001 though 1005 as normal and propagate the headers to masternodes. Masternodes vote and agree, locking block 1000 across the entire network. From here nodes will never process a new block because block 1000 is actually invalid. To solve, the offensive chainlock is removed and the previous chainlock is set as the latest valid one. Meaning blocks can technically rollback to 995 but not any deeper. We know block 995 is valid because when forming the chainlock at block 1000 the network ensures the previous chainlock exists and is a valid chain at 995. Therefore, since it is the last valid chainlock state, we can roll back to it safely and proceed to create a valid chain from that point forward. Having designed to solve these attack vectors we retain the antifragility of relying on PoW (of Bitcoin’s network no less) for the ultimate source of truth while enabling finality via PoS of masternodes agreeing on the chain tip every 5th block which practically eliminates selfish-mining concerns. This finality connects directly to PoDA and its pruning, which we will talk about next.
Proof of Data Availability (PoDA)
Now, with a good understanding of Syscoin’s basis for secure finality that does not compromise the antifragility properties of our PoW, we can segway into Syscoin’s approach to Data Availability. PoDA calls for pruning raw data received by nodes processing blocks and leaving just the hash of that data in its place. Ethereum is also doing this with EIP-4844 using KZG commitments. While our general strategies are similar, Syscoin brings several important differences that promote better decentralization, performance, and overall security.
1.Syscoin uses Keccak-based blobs.
- No trusted setup
- Quantum safe
- Very performant.
2.Syscoin does not shard data. Every full node processes blobs fully.
- Trust yourself only
- Fewer attack vectors
- Data is simple to reproduce and check
3.Syscoin can prune data much quicker, and tie in pruning with finality + 6 hours.
Hash-based Blobs
On point one, we promote the use of hash-based blobs. But importantly, why does Ethereum utilize a KZG polynomial commitment scheme in the first place instead of the more efficient approach using Keccak?
The answer is, because of Ethereum’s sharding design where validators store only a subset of data in chunks (similar to how traditional distributed database nodes store only a small portion of the entire database). Ethereum needs an efficient way to check if these separate chunks are a valid part of the entirety, and to prove that the data is correct. This is important for ZK (validity proof) rollups for which data hashes are fed to the ZK verifier to confirm they are processing state correctly from one to the next.
Within ZK rollups, it is very expensive to check KZG commitments directly. This is due to the number of constraints within the ZK circuit. The expectation is that ZK rollup providers will give a polynomial commitment to the data in their own efficient way native to their cryptographic plumbing, as well as provide a way to check that the commitment matches the KZG commitment which is itself polynomial. There is a simple way to check if two totally separate commitments map to the same input (data), using the equivalence protocol. Ideally, the commitment scheme should be hash-based to avoid trusted setups and ensure quantum safety. However, most of the hash algorithms used in ZK circuits are new and completely untested in the real world (their security is not proven). Clearly they would prefer to use the merkle-root SHA256 hash-based scheme, but it doesn’t fit the sharding design philosophy! For them, KZG is the most efficient way, but it comes with a trusted setup! In contrast, sharding is not a concern for Syscoin, opening the way to some significant advantages. Our philosophy is one where every node trusts only itself. We don’t need a polynomial commitment scheme. However, if ZK circuits cannot work with existing hash-based algorithms like SHA256 or Keccak, then it presents a challenge on how we will work with ZK rollups in the future. The great news is there are advancements in this area, e.g. Hermez zkEVM is using Keccak in Plonky2 for its own data commitment scheme in the ZK prover and verifier, although this might change out of necessity due to Ethereum’s own requirements. However, this indicates it is possible to use a secure, quantum safe hash function to represent data commitments within validity rollups.
In addition to security, this is much better performance-wise, even considering that Syscoin’s full nodes check the entire set of data at every block for data availability. Syscoin provides up to 64 megabytes per block and up to 32 blobs (2 megabytes each) of space available per block (2.5 minutes on average). The blob size fits nicely within our existing fee-market on Syscoin’s native UTXO chain. We simply discount the weight of the block by 100x. That is to say a full block of 64 megabytes accounts for 640kb, leaving 360kb of effective weight in a 1MB block for regular transactions. The fee-market for blobs is discounted 100x from regular transactions, while the rest of the fee-market logic remains consistent with bitcoin mechanics tried and tested over a number of years. In Ethereum’s alternative sharded setup, 32 blobs of 2 MB each are aggregated in a KZG verification which takes roughly 3 seconds (about 2 seconds for each individual blob), while Syscoin’s Keccak-based blob takes about 1 millisecond to check. That is a 2000x performance savings (2000ms per blob vs 1ms per blob). Given the fact that we use a compact block based strategy to disseminate blocks around the network, and that these blobs would have been checked in-between blocks as transactions entering the mempool (cached as a result), when a compact block arrives (only a few kilobytes of data) the resulting blob does not have to be re-checked. This leads to block propagation with minimal overhead and good stability (a key metric when dealing with decentralization of a chain). Blocks being slow and steady at a target of 2.5 minutes, gives sufficient time to propagate blobs and verify/cache them for inclusion in a block. The overhead of PoDA is minimal during run-time and maximizes decentralization whilst fulfilling the fully-secure censorship resistance criteria for rollups. We envision every layer 2 and layer 3 scaling up in secure ways in our system while taking advantage of PoDA due to its simplicity and efficiency, while still having the advantage of Validium for short-term DeFi strategies where DA can be kept off-chain. Think GameFi, TradeFi, and Metaverse objectives. Once account abstraction becomes mainstream, we will see the separate strategies leading to unique DA isolated environments each focused on the required settlement security for short/medium and long-term needs of DApp (distributed application) users.
Pruning in PoDA
The final piece to understand PoDA is how the protocol removes raw data after network participants have had the opportunity to archive it. Upon receipt of a new chainlock, the protocol prunes data older than or equal to six hours of age from the time of the previous chainlock. Since the previous chainlock is effectively the guaranteed finality of the chain, we depend upon it for data removal. The age of the data is based on the time difference between the last guaranteed finality, and the median time-stamp of the block that included the data blob.
Another World’s First — Inherited L1 Security with L2 Variable Gas Rate Dominance
Rollups today inherit the security of the base layer (Ethereum) by paying a variable fee based on the size of the batch of transactions settling from layer 2. With PoDA integrated into Bedrock this fee falls down drastically to just 1400 gas per batch (which itself is 2MB of transactions). Since the BatchInbox smart contract can take a variable number of batches (called blobs) to verify them via the data precompile they will be negligible in the overall cost of a layer 2 transaction. The rollup sequencer may pay 2000 gas (including overhead for the contract) for every 2MB of transactions (roughly 30000 transactions at 70 bytes per L2 transaction compressed) or roughly around only 15 gas per transaction.
Without a rollup those 30000 transactions would cost 630M gas. Using Optimism Bedrock on Ethereum today would cost roughly 32M gas. So Optimism brings around 20x savings from native Ethereum. With PoDA savings range from 315000x cheaper than native Ethereum to 16500x cheaper than Optimism Bedrock on Ethereum today. Note that there is also a small fee of around the same to put the data in PoDA on the UTXO chain as well.
There are rollups and designs where rollups do not store data on Ethereum and instead use offchain data availability to match this cost (celestiums, validiums), but they do so by making a big tradeoff on security by not using the same settlement layer to secure the data required for censorship resistance. For the first time in the world there is now an example where the costs are dominated by only the L2 variable gas rate (15m gas target in Optimism Bedrock governed by an EIP-1559 market) whilst inheriting the full settlement layer 1 security for the rollup. This hasn’t been possible for any other rollup prior to our own, nor among any of the side-chain concepts. There are advantages where accounts may leverage offchain data availability for even cheaper transactions for short-term use cases. These advantages can be unlocked through account abstraction concepts where wallets are actually smart contracts, leading to choices for users on authorization models and where data availability is used on-chain (secure, decentralized) and off-chain (slightly less secure, less costs). Our job is to scale up the settlement layer (Layer 1) while providing the maximum utility and efficiency, leveraging every bit and byte available to us in a way to prevent censorship within a modular blockchain design. We believe this design is the state-of-the-art in maximizing efficiency and therefore making things as cheap as possible by enabling rollups to not be dominated by gas fees of data markets on layer 1 and to be dominated more by gas markets for computation/state storage on layer 2. There is no sacrificing decentralization for us. We only contextualize scaling one way — security first. And we have just proven a vast improvement over status-quo without any tradeoffs.
Ethereum plans to match this sort of design with EIP-4844 and later Data-Availability sampling. However tradeoffs still exist:
- A trusted setup is required, a backdoor is technically possible to completely censor the entire data availability protocol on the settlement layer. Not likely but possible. There is no provable way to prove that the trusted setup was not confiscated or not done correctly.
- Not quantum resistant due to the need for a polynomial commitment scheme with a pairing assumption.
- Requiring new mechanics to work with data, to validate data externally from the clients instead of the simply tooling around Keccak hashing we use in PoDA.
- Sharding can theoretically improve throughput but requires longer liveness prior to pruning because of collusion possibilities and generally more edge-cases for attacks. Also introduces risk in complexity and goes against our philosophy of you only need to trust yourself and can validate the state of your chain yourself without trusting anyone else (Sharding requires an assumption that the data is generally available through half of the nodes and each node validates their own shard is committed to the entire blob). In our case we prune after only 6 hours of the previous chainlock (finality event), and there are no new edge-cases created using hash-based blobs since the blockchain itself assumes security of the hash construction with a great degree of Lindy effects.
- Proof-time of KZG and verifying the batch is more expensive. When a block is formed the entire batch needs to be validated, where a KZG Batch validation would check the entire blob (all shards included). In our tests we found Keccak hash-based blobs 2000x faster to verify and an immeasurable amount of times faster to create the hash versus the KZG commitment of a blob. This leads to less overhead on block propagation, validation and generally better decentralization principles for the existing blockchain design inherited from Bitcoin.

1y ago•
bullish:
1
bearish:
0
Share

 Manage all your crypto, NFT and DeFi from one place
Manage all your crypto, NFT and DeFi from one placeSecurely connect the portfolio you’re using to start.

bullish:
0
bearish:
0

bullish:
0
bearish:
0

