Theta EdgeCloud Tests Prefill/Decode Disaggregation for Large-Scale LLM Serving
1
0

The Theta EdgeCloud team has completed a benchmark testing a more efficient way to serve large language models in production.
LLM inference involves two phases of work, namely prefill and decode, that sit awkwardly together on the same hardware. Splitting them apart, so that each runs on GPUs suited to its demands, lets the whole system run faster and more predictably. The benchmark showed this working on a 235-billion-parameter model across two NVIDIA H200 servers, with response times that barely moved as queries grew much longer, and performance that compared favourably to a well-established commercial offering.
Under matched workloads, the EdgeCloud setup outperformed Together.ai’s serverless endpoint on first-token latency and burst performance, with stronger throughput under steady load.
Together.ai held a slight edge during very long continuous tests, which is a fair and useful finding for anyone weighing where the approach fits today.
The Logic Behind the Architecture
When a large language model answers a query, it carries out two distinct phases of work. The first phase, known as prefill, processes the entire input prompt and builds a kind of working memory called the KV cache, which the model uses to generate its response. The phase is compute-heavy and benefits from raw processing throughput.
The second phase, decode, generates the response one token at a time, reusing that cache. It is memory-bandwidth-bound and sensitive to delay, since each new token depends on the one before it.
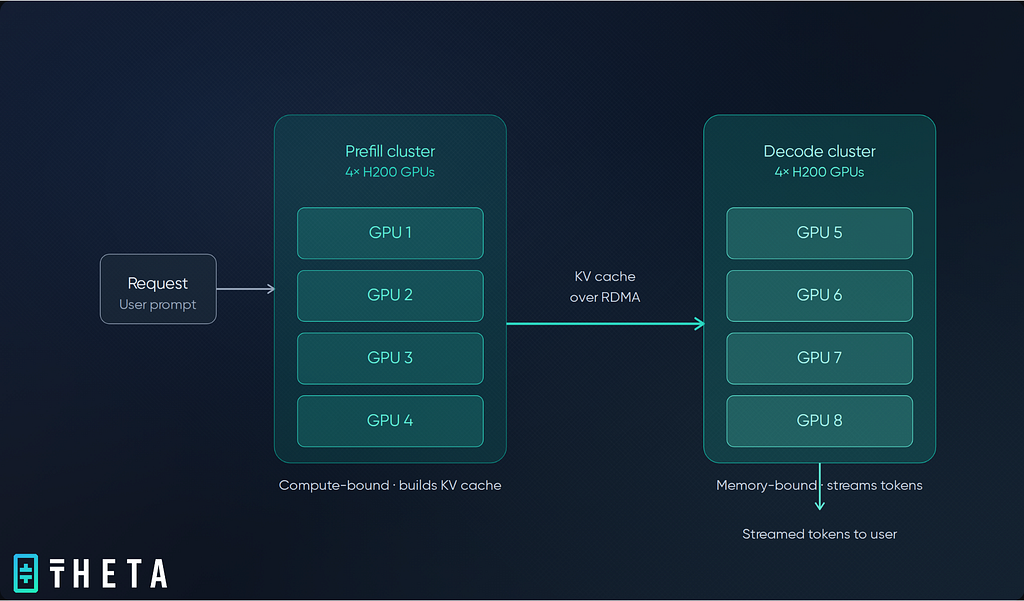
Most AI deployments run both phases on the same pool of GPUs. The result is that the two kinds of work get in each other’s way. A long incoming prompt can slow down the responses other users are currently receiving, because both phases are competing for the same hardware even though they have very different needs.
Disaggregation separates them. One set of GPUs handles prefill. A different set handles decode.
The two communicate over a high-speed network link, with the prefill nodes passing the working memory to the decode nodes once they are done. The main technical challenge is making that handoff fast enough to be worth doing, and recent progress in a networking technology called RDMA, which lets servers share data with very low delay, has made the approach practical at scale.
What the Deployment Looked Like
The EdgeCloud setup used two H200 servers, with four GPUs allocated to prefill and four to decode, connected over a high-speed RDMA link running over RoCE. The benchmark covered prompt lengths from 64 to 4,096 words, up to 32 simultaneous requests, and a mix of steady, burst, and sustained workloads.
The most notable result was how consistent response times stayed as prompts got longer. The time it took for the first word of a response to appear was around 783ms for 1,000-word prompts, 777ms for 2,000-word prompts, and 794ms for 4,000-word prompts. Quadrupling the input length produced almost no change in how long users waited for the response to begin. Because the decode GPUs are kept separate from whatever prefill work is happening, generation speed stays steady regardless of how long the incoming queries are.
For organisations running AI workloads in production, the practical result is infrastructure that holds up better under real-world conditions, where prompt lengths and traffic vary constantly. Heavy users with long queries no longer slow down everyone else, performance becomes more predictable, and operators can add capacity to whichever phase is under pressure without having to expand both at once.
The work fits into a broader direction at Theta EdgeCloud around getting more useful output from existing GPU supply. The global shortage of high-end AI chips will not ease quickly, since semiconductor manufacturing capacity takes years to build out. Better organisation of the hardware that is already deployed is one of the more direct ways to expand what is possible today, and as frameworks like vLLM continue to mature, disaggregated serving is likely to become a standard part of how large models are delivered in production.
To keep up to data with the research happening at Theta, follow us on X, Telegram, Medium, LinkedIn or Facebook.
Theta EdgeCloud Tests Prefill/Decode Disaggregation for Large-Scale LLM Serving was originally published in Theta Network on Medium, where people are continuing the conversation by highlighting and responding to this story.
1
0
 Manage all your crypto, NFT and DeFi from one place
Manage all your crypto, NFT and DeFi from one placeSecurely connect the portfolio you’re using to start.