On-demand Model APIs — Serverless AI development powered by Theta EdgeCloud
0
0
On-demand Model APIs — Serverless AI development powered by Theta EdgeCloud

Theta continues to innovate and is pleased to announce the first decentralized On-demand AI Model API Service, making it easier than ever for developers to incorporate new AI models for any type of use case. To-date one of the biggest challenges for AI developers is the need to build infrastructure from scratch to host and run their AI models, this is both costly and time consuming.
The new On-demand AI Model API Service enables serverless development for building and scaling intelligent applications. With this product, you can now access powerful AI models — ranging from cutting-edge LLMs to GenAI models — instantly via a simple API, without the hassle of provisioning or managing servers. Whether you’re prototyping a smart assistant or deploying a production-grade AI solution, the pay-as-you-use model ensures AI developers only pay for what you use, while the Theta EdgeCloud platform handles the rest. It’s the fastest and most cost-effective way to bring AI into your apps — no infrastructure, no overhead, just plain simple API integration powered by Theta blockchain.
As we build toward EdgeCloud being the most user-friendly, feature-rich decentralized bandwidth and compute platform in the market, our #1 focus remains adoption and increasing usage of the Theta edge network. This in turn drives increased usage of Theta blockchain, velocity and utility of TFUEL tokens and ultimately better economics, security and governance by owning and staking THETA tokens.
More importantly, this new service enables EdgeCloud to manage AI model execution at much more granular levels such as by image generated, token used and work produced, thereby setting up the foundation for a fully hybrid GPU edge network beginning with the June 2025 release. This enables the system to intelligently allocate and optimize jobs to less powerful edge 3090/4090 and 5000 series NVidia GPU nodes vs data center A100s and H100s.
In the backend, these AI models run on Theta EdgeCloud’s hybrid cloud-edge infrastructure , which dynamically sources idle GPU capacity from cloud providers, enterprise data centers, and community-operated edge nodes. Based on the real-time demand for model inference, an intelligent scheduler continuously optimizes model placement and resource allocation, ensuring low latency, high availability, and cost efficiency — even during peak hours. This distributed architecture allows the platform to scale seamlessly while minimizing waste and delivering consistent performance for development and production workloads.
EdgeCloud will offer below models APIs at launch:
- FLUX.1-schnell: text to image
- Llama 3.1 70B Instruct: LLM
- Whisper: audio to text
- Stable Diffusion Turbo Vision: text to image
- Image to Image: image to image, e.g. art style transfer, object erasing, in-painting, background removal, image upscaling
- Llama 3 8B: LLM
- Stable Diffusion XL Turbo: text to image
- Stable Diffusion Video: text to video
Among these, we have verified that the following models can run efficiently on commercial-grade community GPUs including Nvidia RTX 4070/4090s. After Theta EdgeCloud’s June 2025 EdgeCloud client release, community operated GPU nodes can host these models and others to provide model API services for job rewards paid in TFUEL:
- Whisper: audio to text (at least 12GB vRAM needed, e.g. RTX4070)
- Stable Diffusion XL Turbo: text to image (at least 12GB vRAM needed, e.g. RTX4070)
- Image to Image: image to image, e.g. art style transfer, object erasing, in-painting, background removal, image upscaling (at least 16GB vRAM needed, e.g. RTX4090)
Start now with On-Demand Model API Service
The On-Demand Model API Service can be accessed HERE. The link will take you to a dashboard similar to the one shown below, featuring a curated list of the most popular and cutting edge AI models, including Flux, Llama 3.1, Whisper, Stable Diffusion, and others.

To use the model, click the green “View” button. You can also find the API pay-as-you-use pricing details displayed just above the “View” button (for example, by image, by tokens, etc)
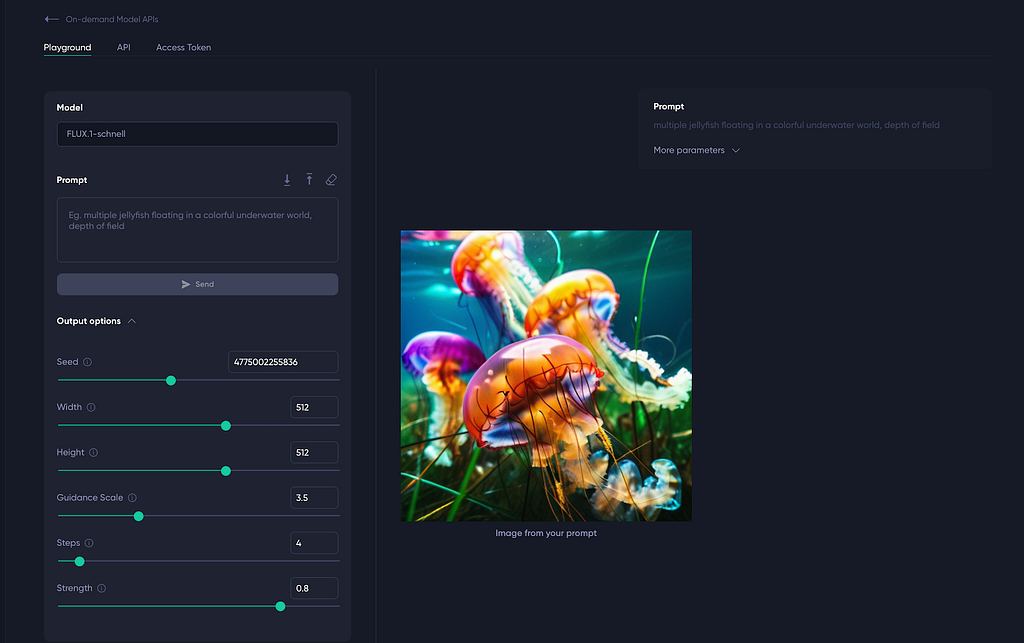
Using FLUX.1-schnell as an example, after clicking the “View” button, you’ll be taken to a page with three tabs. The first tab, “Playground”, allows you to interact with the model directly through the UI. For instance, the Playground for FLUX.1-schnell accepts a text prompt along with generation parameters such as image resolution, and generates an image based on your input when you click the “Send” button.
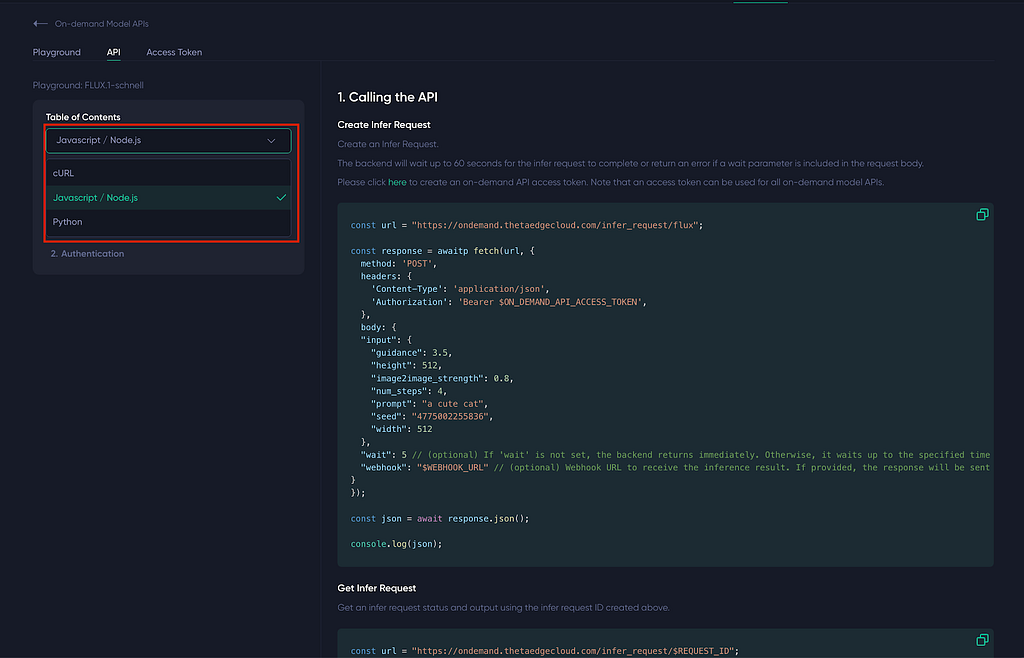
The second tab is particularly useful for developers, as it provides detailed API documentation for the currently selected model. It includes API specifications and example code snippets in multiple languages, such as cURL, JavaScript / Node.js, and Python. You can select your preferred language from the dropdown menu highlighted in the red box.
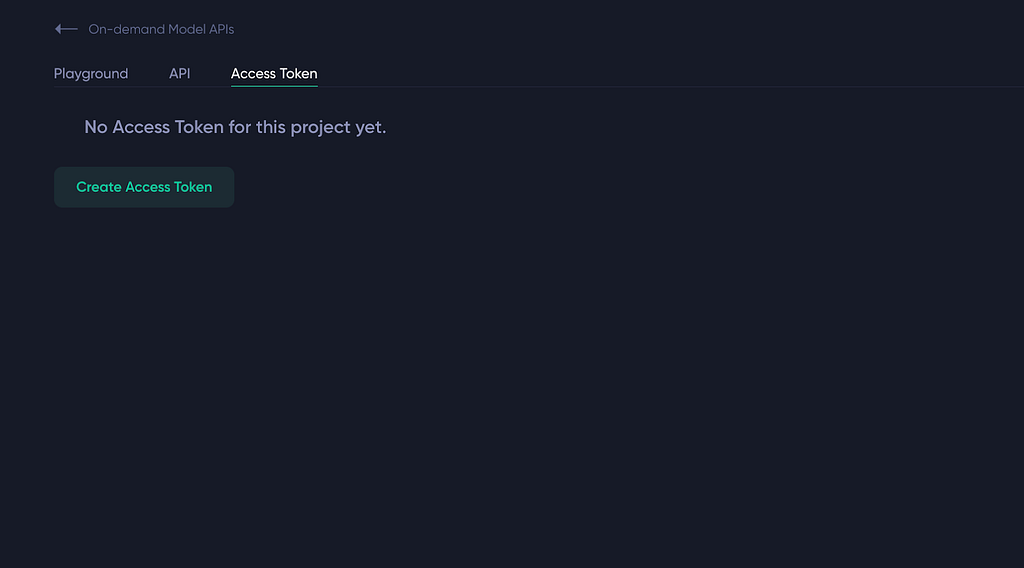
Accessing the model APIs requires an access key, which you can manage in the third tab. You can generate as many access keys as needed, and each one can be renamed, updated, or deleted at any time. Note that these access tokens are valid across all model APIs.
While the on-demand AI model APIs are handy for serverless development, there are times where the developers might want dedicated model deployments to optimize performance and latency. For this you can use Dedicated AI Model Serving already available on Theta EdgeCloud.
On-demand Model APIs — Serverless AI development powered by Theta EdgeCloud was originally published in Theta Network on Medium, where people are continuing the conversation by highlighting and responding to this story.
0
0
 Manage all your crypto, NFT and DeFi from one place
Manage all your crypto, NFT and DeFi from one placeSecurely connect the portfolio you’re using to start.



0
0
