Introducing Advanced Parallel EVM: Parallel I/O via Programmable Access List and Intelligent I/O…
27d ago•
bullish:
2
bearish:
0
Share
Introducing Advanced Parallel EVM: Parallel I/O via Programmable Access List and Intelligent I/O Preloading

Parallel EVM emerges as a standout solution for enhancing EVM execution speeds. By leveraging parallel program execution and data read/write operations, it taps into the concurrency capabilities of modern computers, which are typically equipped with 4–8 CPU cores and boast high-bandwidth I/O.
There are two main approaches to implementing Parallel EVM:
- Parallel Execution: This involves executing transactions concurrently in an optimistic manner and resolving any conflicts. If conflicts arise, the transactions that were executed optimistically are re-executed.
- Parallel I/O: This strategy aims to reduce latency and boost performance by reading EVM data in parallel.
Of these strategies, parallel I/O has garnered considerable interest within the Ethereum community for its simplicity and potential to significantly enhance performance. As shown in the below graph, reading data using SLOAD and CALL opcodes in the EVM accounts for approximately 70% of EVM execution time.
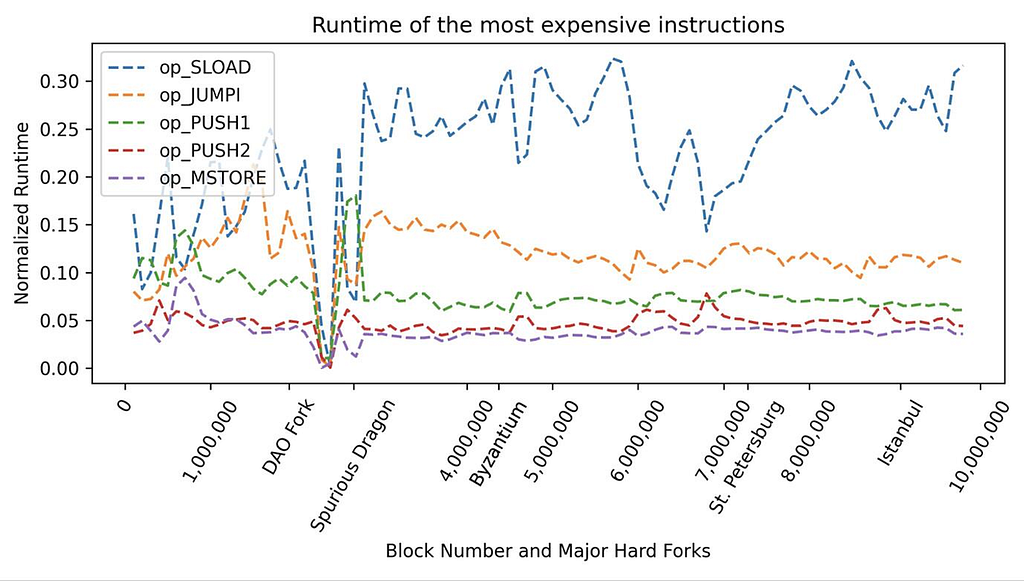
Graph from https://collective.flashbots.net/t/speeding-up-the-evm-part-1/883
A key milestone in exploiting parallel I/O’s advantages is EIP-2930: Optional Access Lists, which marks a pioneering step by integrating optional access lists into transactions. This approach allows for the parallel preloading of data from access lists, enhancing I/O speed and reducing gas costs per transaction. Despite these advantages, access lists remain underutilized on the mainnet, with only about 1.45% of transactions including them, as noted in a study from https://arxiv.org/abs/2312.06574.
This article delves into two promising strategies to further harness parallel I/O’s benefits:
- EIP-7650: Programmable Access Lists, which enables contracts to define multiple data locations for parallel preloading. This method can sustainably reduce latency of reading multiple data and thus lower gas costs beyond what EIP-2930 offers.
- Intelligent I/O Preloading: By designing an EVM capable of learning the constant read operations (SLOAD and CALL) within a contract method, it can preload data in parallel during contract method invocation, thus leveraging I/O parallelization benefits even without explicit access lists.
Exploring Storage Performance: Sequential vs Parallel
Before delving into parallel I/O in the EVM, it’s crucial to understand the capabilities of modern storage devices regarding parallel I/O operations. To shed light on this, we conducted tests on a Western Digital SN850x 4TB NVMe disk, priced at approximately $300, to evaluate how it handles varying numbers of parallel I/O requests and the impact on latency per I/O. In these tests, a single I/O operation represents a sequential workload, akin to the current EVM approach. Our findings revealed that executing four parallel I/O operations yields latency figures comparable to a sequential execution. Moreover, increasing the parallelism to twelve I/O operations results in a latency increase of roughly 12% (from 54.25 to 60.79), when compared to the sequential execution.
This data highlights the potential for leveraging parallel I/O in environments like the EVM, where enhancing storage access efficiency can significantly increase overall EVM performance.
Parallel EVM emerges as a standout solution for enhancing EVM execution speeds. By leveraging parallel program execution and data read/write operations, it taps into the concurrency capabilities of modern computers, which are typically equipped with 4–8 CPU cores and boast high-bandwidth I/O.
There are two main approaches to implementing Parallel EVM:
- Parallel Execution: This involves executing transactions concurrently in an optimistic manner and resolving any conflicts. If conflicts arise, the transactions that were executed optimistically are re-executed.
- Parallel I/O: This strategy aims to reduce latency and boost performance by reading EVM data in parallel.
Of these strategies, parallel I/O has garnered considerable interest within the Ethereum community for its simplicity and potential to significantly enhance performance. As shown in the below graph, reading data using SLOAD and CALL opcodes in the EVM accounts for approximately 70% of EVM execution time.
Graph from https://collective.flashbots.net/t/speeding-up-the-evm-part-1/883
A key milestone in exploiting parallel I/O’s advantages is EIP-2930: Optional Access Lists, which marks a pioneering step by integrating optional access lists into transactions. This approach allows for the parallel preloading of data from access lists, enhancing I/O speed and reducing gas costs per transaction. Despite these advantages, access lists remain underutilized on the mainnet, with only about 1.45% of transactions including them, as noted in a study from https://arxiv.org/abs/2312.06574.
This article delves into two promising strategies to further harness parallel I/O’s benefits:
- EIP-7650: Programmable Access Lists, which enables contracts to define multiple data locations for parallel preloading. This method can sustainably reduce latency of reading multiple data and thus lower gas costs beyond what EIP-2930 offers.
- Intelligent I/O Preloading: By designing an EVM capable of learning the constant read operations (SLOAD and CALL) within a contract method, it can preload data in parallel during contract method invocation, thus leveraging I/O parallelization benefits even without explicit access lists.
Exploring Storage Performance: Sequential vs Parallel
Before delving into parallel I/O in the EVM, it’s crucial to understand the capabilities of modern storage devices regarding parallel I/O operations. To shed light on this, we conducted tests on a Western Digital SN850x 4TB NVMe disk, priced at approximately $300, to evaluate how it handles varying numbers of parallel I/O requests and the impact on latency per I/O. In these tests, a single I/O operation represents a sequential workload, akin to the current EVM approach. Our findings revealed that executing four parallel I/O operations yields latency figures comparable to a sequential execution. Moreover, increasing the parallelism to twelve I/O operations results in a latency increase of roughly 12% (from 54.25 to 60.79), when compared to the sequential execution.
This data highlights the potential for leveraging parallel I/O in environments like the EVM, where enhancing storage access efficiency can significantly increase overall EVM performance.
Parallel EVM emerges as a standout solution for enhancing EVM execution speeds. By leveraging parallel program execution and data read/write operations, it taps into the concurrency capabilities of modern computers, which are typically equipped with 4–8 CPU cores and boast high-bandwidth I/O.
There are two main approaches to implementing Parallel EVM:
- Parallel Execution: This involves executing transactions concurrently in an optimistic manner and resolving any conflicts. If conflicts arise, the transactions that were executed optimistically are re-executed.
- Parallel I/O: This strategy aims to reduce latency and boost performance by reading EVM data in parallel.
Of these strategies, parallel I/O has garnered considerable interest within the Ethereum community for its simplicity and potential to significantly enhance performance. As shown in the below graph, reading data using SLOAD and CALL opcodes in the EVM accounts for approximately 70% of EVM execution time.
Graph from https://collective.flashbots.net/t/speeding-up-the-evm-part-1/883
A key milestone in exploiting parallel I/O’s advantages is EIP-2930: Optional Access Lists, which marks a pioneering step by integrating optional access lists into transactions. This approach allows for the parallel preloading of data from access lists, enhancing I/O speed and reducing gas costs per transaction. Despite these advantages, access lists remain underutilized on the mainnet, with only about 1.45% of transactions including them, as noted in a study from https://arxiv.org/abs/2312.06574.
This article delves into two promising strategies to further harness parallel I/O’s benefits:
- EIP-7650: Programmable Access Lists, which enables contracts to define multiple data locations for parallel preloading. This method can sustainably reduce latency of reading multiple data and thus lower gas costs beyond what EIP-2930 offers.
- Intelligent I/O Preloading: By designing an EVM capable of learning the constant read operations (SLOAD and CALL) within a contract method, it can preload data in parallel during contract method invocation, thus leveraging I/O parallelization benefits even without explicit access lists.
Exploring Storage Performance: Sequential vs Parallel
Before delving into parallel I/O in the EVM, it’s crucial to understand the capabilities of modern storage devices regarding parallel I/O operations. To shed light on this, we conducted tests on a Western Digital SN850x 4TB NVMe disk, priced at approximately $300, to evaluate how it handles varying numbers of parallel I/O requests and the impact on latency per I/O. In these tests, a single I/O operation represents a sequential workload, akin to the current EVM approach. Our findings revealed that executing four parallel I/O operations yields latency figures comparable to a sequential execution. Moreover, increasing the parallelism to twelve I/O operations results in a latency increase of roughly 12% (from 54.25 to 60.79), when compared to the sequential execution.
This data highlights the potential for leveraging parallel I/O in environments like the EVM, where enhancing storage access efficiency can significantly increase overall EVM performance.

EIP-7650: Programable Access Lists
In response to the incredible low adoption of EIP-2930: Optional Access List, EIP-7650: Programmable Access Lists has been introduced, aiming to maximize the sustained benefits of using access lists. This proposal enables smart contract developers to define an access list when a contract is called at the early beginning. For instance, consider the swap() method in Uniswap V2. Each swap operation necessitates reading specific storage slots, including:
- token0 address
- token1 address
- reserves of token0 and token1
- price0CumulativeLast
- price1CumulativeLast
Additionally, it involves reading the contracts for token0 and token1. This process incurs a significant latency, estimated at $7 T$ where $T$ is the latency for reading an EVM state, thus considerably slowing down each swap() execution.
EIP-7650 introduces a prefetch interface in the EVM, allowing for a programmable access list that can preload all necessary data in parallel. The below code shows an example code to include prefetch interface in UniswapV2 swap(). The code will ask the EVM to preload all five storage slots in parallel and then read the two token contracts at once. By doing so, it aims to significantly reduce the latency from seven individual reads to just two reads given the latency of parallel reads is the same as that of the sequential one.
// this low-level function should be called from a contract which performs important safety checks
function swap(uint amount0Out, uint amount1Out, address to, bytes calldata data) external lock {
prefetch {
token0.slot,
token1.slot,
reserve0.slot,
price0CumulativeLast.slot,
price1CumulativeLast.slot,
} // add the storage keys `accessed_storage_keys`
prefetch {
token0,
token1,
} // add the contracts of token0 and token1 to `accessed_addresses`
...
}
In terms of gas savings, if we assume that the gas cost for reading five slots/contracts equates to that of a single operation (given latency is a primary factor in gas cost calculations for SLOAD/CALL), the gas cost could potentially be reduced from 2100 * 5 + 2600 * 2 = 15700 to 2100 + 2600 = 4700, thereby saving 10,000 gas per swap transaction. As a result, this approach not only reduces latency but also optimizes gas expenditure in smart contract operations.
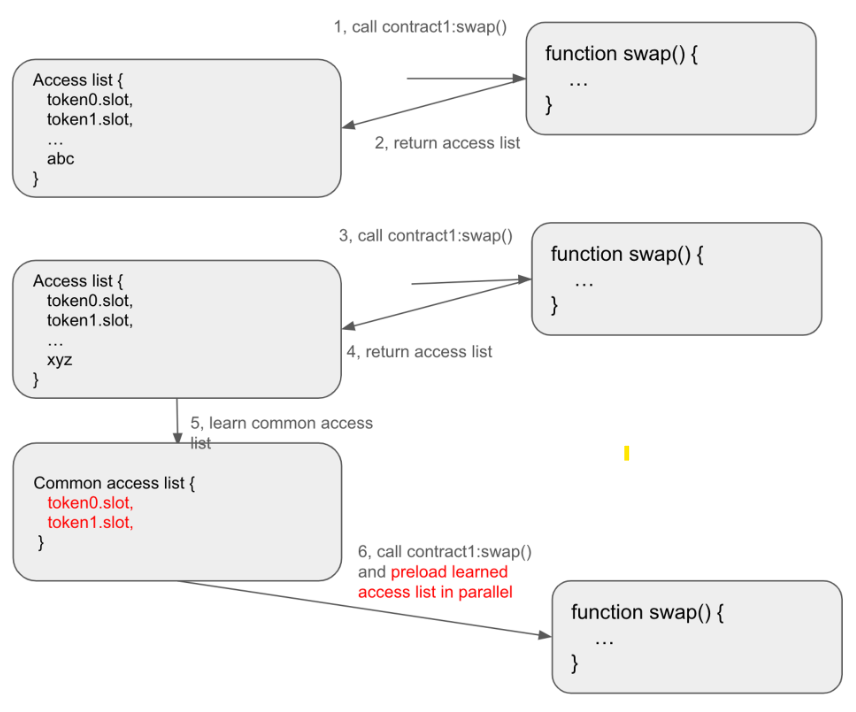
Intelligent I/O Preloading
For those keen on the mechanics of the Uniswap V2 swap() function, it's noticeable that this operation consistently requires access to five specific storage slots and two token contracts. This consistent pattern presents an opportunity for optimization through intelligently learning the read pattern and preloading the reads thereafter. By identifying and learning the common data reads associated with a contract's method, it's possible to preload this data in parallel before the contract is invoked.
Implementing such intelligent I/O parallelization could significantly enhance the efficiency of contract execution. While the exact impact on gas savings might vary (since the adoption of this optimization depends on the implementation by different EVM clients), the potential for consistently reduced I/O latency is clear.
Concluding Remarks
In this article, we explored two innovative strategies aimed at enhancing the utilization of access lists, thereby maximizing the advantages of parallel I/O. The first method empowers smart contract developers to proactively define the access list within their code, facilitating consistent benefits from parallel I/O operations, such as reduced latency. The second strategy, Intelligent I/O Preloading, leverages the observation of frequently accessed data by learning the common read patterns of a contract’s method and preloading this data in parallel in the following calls accordingly.
While the direct impact through these approaches may not be immediately quantifiable, they lay the groundwork for significant enhancements in the efficiency of Ethereum’s network. By adopting these strategies, future Ethereum clients could potentially achieve higher transaction throughput and reduced operational costs, marking a step forward in the blockchain’s evolution toward scalability.
- Website: https://www.quarkchain.io
- Telegram: https://t.me/quarkchainio
- Discord: https://discord.me/quarkchain
- Twitter: https://twitter.com/Quark_Chain
- Medium: https://medium.com/quarkchain-official
- Reddit: https://www.reddit.com/r/quarkchainio/
- Developer Community: https://community.quarkchain.io/
27d ago•
bullish:
2
bearish:
0
Share
 Manage all your crypto, NFT and DeFi from one place
Manage all your crypto, NFT and DeFi from one placeSecurely connect the portfolio you’re using to start.

bullish:
0
bearish:
0

bullish:
0
bearish:
0

bullish:
0
bearish:
0

bullish:
0
bearish:
0